고정 헤더 영역
상세 컨텐츠
본문
# SQL
# 3.2.1 Basic Types
vatiety of built-in types in SQL
- char(n) : fixed-length(n) character string
- varchar(n) : variable-length character string with user-specified maximum length n
- int : machine-dependent
- smallint : machine-dependent
- numeric(p, d) : 총 p자리의 숫자, 그 중 소숫점 밑이 d자리. ex) numeric(3,1) => 44.5
- real, double : machine dependent
- float(n): at least n digits
모든 타입은 null을 가질 수 있다( null은 value indicates an absent or unknown )
# 3.2.1-1 char과 varchar
char(10)에 "yang"을 저장한다면, 10자리로 맞추기 위해 'space'를 붙일 것이다.
varchar(10)에 저장된 "yang"은 공백을 추가하지 않을 것이다.
이 둘을 비교연산한다면, 가장 먼저 길이를 같게 하기 위해 짧은 쪽에 공백을 추가할 것이다.
하지만 db에 따라 이러한 공백 추가 작업을 하지 않을 수 있고, 원하는 Bool값을 얻지 못할 수 있으므로,
일관되게 varchar()을 사용하는 것을 recommend
# 3.2.2 Basic Schema Definition
create table r
( A1 D1,
A2 D2,
A3 D3, ...
....
An Dn,
primary key (key name),
foreign key (key name) references name,
<integrity-constraint1>
<integrity-constraint2>....
);
# SQL의 integrity-constraints
## primary key 지정
primary key를 지정하는 것은 Optional이다!! but 지정해주는 것이 일반적이다!
primary key로 지정하면, nonnull & uinque임이 보장된다. ( primarykey가 여러 attribute로 구성되면, 모든 attribute가 nonnull이어야 한다!)
## Foreign key
foreign key (A1, A2,...An)이 다른 table의 s라는 set을 reference한다면,
foreign key에 해당하는 어떤 tuple을 선택하더라도, s에 존재해야한다 ( 참조 무결성 )
## not null
attribute에 지정되며, 해당 domain에 null을 배제(exclude)시킨다.
## SQL은 이러한 integrity constraints를 위반하는 update, insert등이 들어오면 error를 뱉어준다!!
# 테이블 삭제 (drop)
@db에서 relation을 아예 삭제하는 명령
drop table r;
@relation은 그대로 남기고 내부 tuple들만 보두 삭제하는 명령
delete from r;
@존재하는 table에 column 추가하는 명령(모든 값은 Null로 초기화되어 들어간다)
alter table r add A D;
@ 존재하는 table에서 column만 제거 ( 대다수의 DBMS에서 attribute만 drop하는 기능을 지원하지 않음. table drop만..)
alter table r drop A;
# 3.2.3 Basic Structure of SQL Querie
SELECT (원하는 attribute A1, A2... ) FROM 테이블 WHERE predicates
# SQL은 DB relation혹은 SQL result에서 duplication을 허용한다. 중복제거는 time-consuming이기 때문!
# 3.2.3-1 중복제거 distinct
# 중복을 제거하고싶을 때, 우리는 select 뒤에 distinct를 사용한다.
예)
select distinct 컬럼 from 테이블;
# 3.2.3-2 명시적으로 중복제거 안하기 (keyword : all)
예)
select all 컬럼 from 테이블;
하지만 중복을 제거하지 않는 것이 default이기 때문에 사용하지 않아도 된다.
# 3.2.3-3 select절에 arithmetic expression 포함시키기 ( keyword : +, -, *, / )
예)
SELECT ID, name, salary * 1.5 FROM instructor;
# 3.2.3-4 from절에 많은 relation이 있는 경우
from 절에 from r1, r2,r3 와 같이 많은 relation(table)이 있는경우, Cartesian product가 생성이 되고, 이후에 where predicate를 만족하는 tuple들을 걸러내게 된다.
이후, select절에 포함된 attribute만 걸러서 가져오게 된다. 라고 이해하면 쉬움
실제 SQL은 이렇게 비효율적인 방식으로 동작하지는 않는다!
# 3.4 Rename Operation ( as )

이렇게 붙여진 이름들은 SQL에서 correlation name이라고 정의한다.
하지만 table alias = correlation variable = tuple variable이라고도 한다.
# 3.4.2 String Operations
* SQL standart는 영어 대-소문자를 구분하지만 ( case sensitive ), MySQL과 같은 몇몇 DBMS는 대-소문자 구분을 하지 않는다.
따라서 "yang" = "YANG" 은 true이다.
- Percent(%) : % matches any substring (길이 상관x)
- Underscore( _ ) : _ character matches any character ( 문자 하나 )
사용 예시)

- BackSlash(\)
backslash(\)는 특수문자 (special pattern) 바로 앞에 써서 일반문자로 인식하게 한다.
- "ab\%%"는 ab%로 시작하는 모든 strings와 match된다.
- like와 not like
string의 match 여부를 predicate로 줄 때 사용
# 3.4.3 asterisk
*는 all attributes 를 뜻한다.

# 3.4.4 order by
- order by attr 한다면, default로 ascending order이다.
- 두가지 조건을 사용한다면, 첫 조건으로 정렬 후, 같은 것이 있을 때 두 번째 조건으로 정렬하게 된다.
ex) order by salary desc, name asc; 한다면 salary로 내림차순 정렬 후, salary가 같은 경우에 대해서 name asc 정렬하게 된다.
# 3.4.5 where-clause predicates

SQL은 (v1,v2)와 같이 "row constructor"를 사용하여 연산을 진행할 수 있게 해준다.
위의 SQL query를 아래와 같이 좀 더 응축하여 작성할 수 있다.

# 3.5.1 Set Operation
Union Operation

# union은 select와 다르게 모든 duplicate를 제거한다. ( 테이블 하나가 갖고있던 duplicate까지도 모두! )
# duplicate를 제거하고싶지 않다면, union 대신 union all을 사용하면 된다.
Intersect Operation (Mysql에는 Intersect 연산이 없다. )
# Intersect 또한 set operation이기 떄문에 모든 duplicate를 제거한다.
# duplicate를 제거하지 않으려면, Intersect all 을 사용하면 된다.
Except Operation
# except 연산 또한 모든 duplicate를 제거한다. ( 같은 value를 4개, 2개 갖고있다면, result table은 해당 value를 0개 갖는다 )
# duplicate제거를 하지 않기 위해서는 except all 을 사용한다. ( 같은 value를 4개, 2개 갖고있다면, result table은 해당 value를 2개 갖는다 )
# 3.6 Null values
SQL은 null이 포함된 연산의 결과는 무조건 unknown으로 처리한다. 이는 true, false에 이은 세 번째 logical value이다.
where predicate의 결과가 false 혹은 unknown이면, result에 포함하지 않는다!
이어, where 절에서 Boolean operation이 "unknown"에 대하여서도 연산할 수 있게 확장되었다.
중요!!

where 절에서 우리는 is null, is not null, is unknown 등으로 null관련, 혹은 연산의 결과가 unknown인지를 확인할 수 있다.
## 우리가 select distinct를 사용했을 때, duplicate한 tuple을 삭제해야하는데,
corresponding attributes from tuples가 같다고 판단되는 경우는 아래와 같다
1. non-null & equal in value
2. both are null
즉 ("A", null) 과 ("A", null)은 같은 것으로 판단되어 중복 제거된다.
(null, null,null) 과 (null, null, null)도 그렇다
# 3.7 Aggregate Functions

Boolean에는 every와 some등의 aggregate function 을 적용할 수 있다.
count()를 제외한 모든 aggregate function은 null을 ignore한다!
# 3.7 Group By
아래와 같이, group by를 사용할 때는, select절에는
1. group by 에 포함된 attribute
2. aggregated 된 attribute
외에는 다른 attribute가 포함되면 안된다.

# 3.7.1 Having clause
Having 절은 우리가 조건을 tuple에 달아주기보다, group에 달아주고 싶을 때 사용한다!
# group by를 사용할 때의 select 절에서와 같이, having clause에 aggregate없이 등장하는 attribute는 group by에 꼭 있어야한다.
Group by와 Having을 포함한 query의 relational algebra
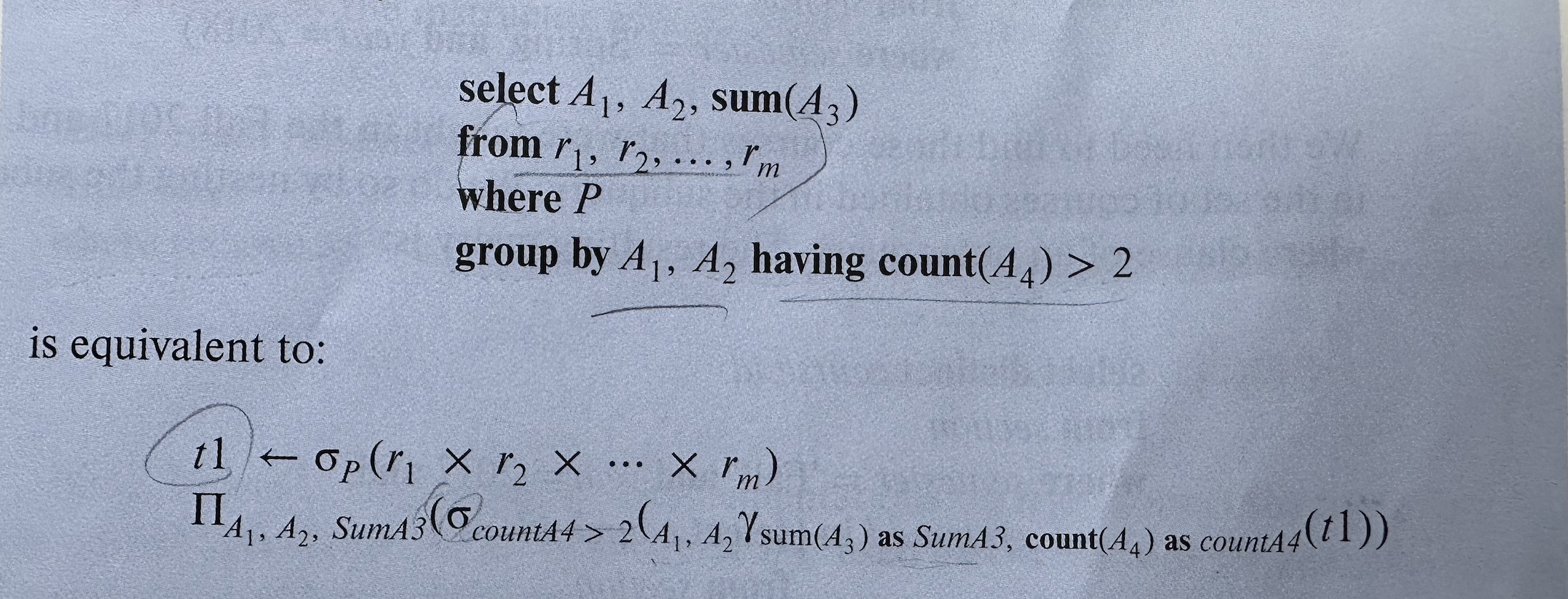
# 3.8.1 Set Membership
in
-> in을 사용할 때는 duplicate제거가 되지 않으므로, 경우에 따라 꼭 distinct를 붙여줘야한다!

not in

# 3.8.2 Set Comparison
Some, all ( <, >, <=, >=, =, <>과 함께 쓴다 )
where salary > all ( select salary from~~ )
having avg(salary) >= all ( select avg(salary) from ~~)


# 3.8.3 Set Comparison
# 3.9 Modification of the Database
Deletion
delete from r where P;
delete 명령은 operates on only one relation!
Insertion




Update


'데이터베이스(DB) System Concepts' 카테고리의 다른 글
| Database System Concepts PART2 - Introduction to the Relational Model (0) | 2022.10.22 |
|---|---|
| Database System Concepts - 1장 Introduction (0) | 2022.09.25 |




